|
|

|

|
| e-Pub |
Section: New Results
Modeling Spatial Layout of Features for Real World Scenario RGB-D Action Recognition
Participants : Michal Koperski, François Brémond.
keywords: computer vision, action recognition
Challenges in action representation in real-world scenario using RGB-D sensor
With RGB-D sensor it is easy to take advantage of real-time skeleton detection. Using skeleton information we can model not only dynamics of action, but also static features like pose. Skeleton-based methods have been proposed by many authors, and have reported superior accuracy on various daily activity data-sets. But the main drawback of skeleton-based methods is that they cannot make the decision when skeleton is missing.
We claim that in real world scenario of daily living monitoring, skeleton is very often not available or is very noisy. This makes skeleton based methods unpractical. There are several reasons why skeleton detection fails in real-world scenario. Firstly, the sensor has to work outside of it's working range. Since daily living monitoring is quite an unconstrained environment, the monitored person is very often too far from sensor, or is captured from non-optimal viewpoint angle. In Figure 6 we show two examples where skeleton detection fails. In the first example, the person on the picture wears black jeans which interferes with sensor. In such a case depth information from lower body parts is missing, making skeleton detection inaccurate. In the second example (see Figure 7) the person is too far from sensor and basically disappears in the background. In this case depth information is too noisy, thus skeleton detection fails. All disadvantages mentioned above will affect skeleton-based action recognition methods, because they strictly require skeleton detection.
On the other hand, local points-of-interest methods do not require skeleton detection, nor segmentation. That is why they received great amount of interest in RGB based action recognition where segmentation is much more difficult than with RGB-D. Those methods rely mostly on detection of points-of-interest usually based on some motion features (eg optical flow). The features are either based on trajectory of points-of-interest or descriptors are computed around the points-of-interest. One of the main disadvantage of those methods is fact that they fail when they cannot "harvest" enough points-of-interest. It happens when action has low dynamics eg "reading a book" or "writing on paper". Such actions contain very low amount of motion coming from hand when writing or turning the pages. In addition local points-of-interest methods very often ignore the spatial layout of detected features.
Proposed method
|

|
To address those problems we propose to replace skeleton detection by RGB-D based people detector. Note that person detection is much easier than skeleton detection. In addition we propose to use two people detectors: RGB and depth based - to take advantage of two information streams.
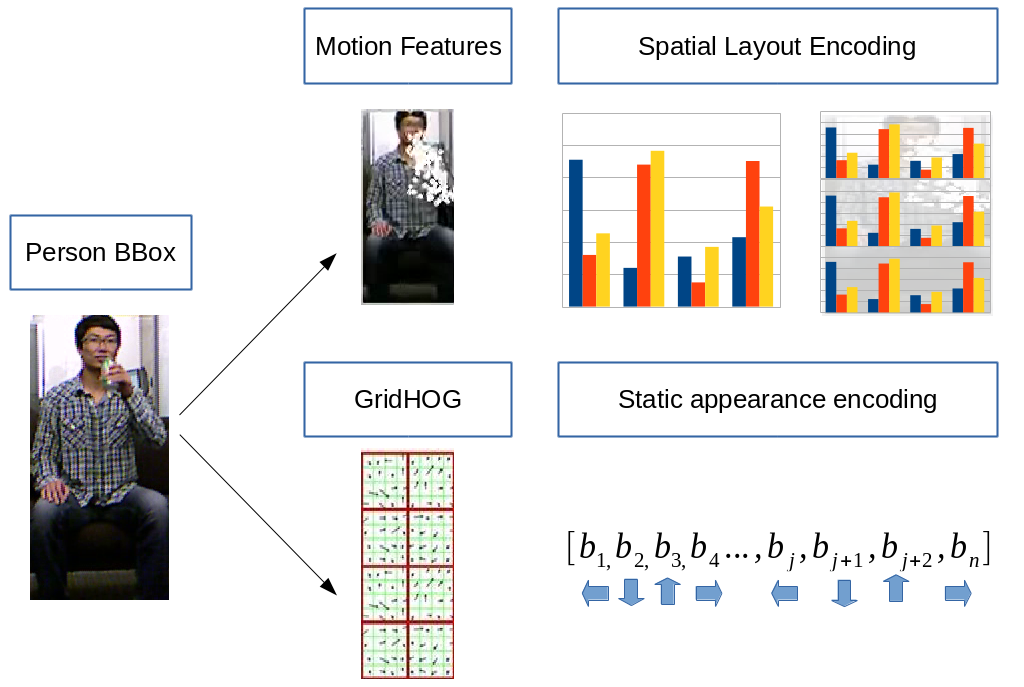
We propose to model spatial layout of motion features obtained from a local points-of-interest based method. We use Dense Trajectories [99] as a point of interest detector and MBH (Motion Boundary Histogram [62]) as a descriptor. To improve the discriminating power of MBH descriptor we propose to model spatial-layout of visual words computed based on MBH (Figure 7). We divide a person bounding box into Spatial Grid (SG) and we compute Fisher Vector representation in each cell. In addition, we show that other spatial-layout encoding methods also improve recognition accuracy. We propose 2 alternative spatial-layout encoding methods an we compare them with Spatial Grid.
To improve recognition of actions with low amount of motion we propose a descriptor which encodes rough static appearance (Figure 7). This can be interpreted as rough pose information. We divide the detected person bounding box into grid cells. Then we compute HOG [61] descriptor inside each cell to form the GHOG (GridHog) descriptor.
Further details can be find in the paper [37]. The contributions of this paper can be listed as follows:
-
We propose to use two people detectors (RGB and depth based ) to obtain person bounding box instead of skeleton.
-
We propose to use Spatial Grid (SG) inside person bounding box. To model spatial-layout of MBH features.
-
We propose to encode static information by using novel GHOG descriptor.
-
We propose two other methods which model spatial-layout of MBH features and we compare them with Spatial Grid.
Experiments
We evaluate our approach on three daily activity data-sets: MSRDailyActivity3D, CAD-60 and CAD-120. The experiments show that we outperform most of the skeleton-based methods without requiring difficult in real-world scenario skeleton detection and thus being more robust (see Table1, Table2 and Table3).
| Method | Accuracy [%] |
| NBNN [94] | 70.00 |
| HON4D [87] | 80.00 |
| STIP + skeleton [106] | 80.00 |
| SSFF [95] | 81.90 |
| DSCF [102] | 83.60 |
| Actionlet Ensemble [101] | 85.80 |
| RGGP + fusion [79] | 85.60 |
| Super Normal [80] | 86.26 |
| BHIM [74] | 86.88 |
| DCSF + joint [102] | 88.20 |
| Our Approach | 85.95 |
| Method | Accuracy [%] |
| STIP [106] | 62.50 |
| Order Sparse Coding [86] | 65.30 |
| Object Affordance [75] | 71.40 |
| HON4D [87] | 72.70 |
| Actionlet Ensemble [101] | 74.70 |
| JOULE-SVM [72] | 84.10 |
| Our Approach | 80.36 |